
Kali ini saya ingin berbagi sedikit tentang pengalaman saya dalam menangani database dalam jumlah besar, yang belum tahu monggo disimak, yang sudah tahu monggo nambahi. hehehe… database merupakan hal pokok dalam sebuah system, ia menyimpan segudang informasi dari informasi penting sampai informasi gak penting, tujuanya satu, supaya informasi yang ada di dalam database tersebut, dapat di peroleh (dicari) dengan cepat, tepat dan akurat. untuk data yang jumlahnya hanya jutaan, mungkinkomputer server yang ada saat ini sudah cukup mumpuni, tapi kalau jumlahnya puluhan juta, atau bahkan ratusan, hm… bisa-bisa loadingnya memakan waktu lama. untuk itu sedikit tulisan ini supaya bisa membantu bagi yang ingin belajar menangani database dalam jumlah besar. sebagai contoh saya membuat sebuah database sederhana dengan jumlah data sekitar 1 juta data. tentu pada kehidupan nyata jumlah data ini tidak ada apa-apanya. oke, silakan menyimak.

ERD
Gunakan Index, Primary, dan Unique
pengguna’an Index pada sebuah table merupakan hal yang sangat penting, mengingat index ini nantinya akan dijadikan sebagai acuan dalam pencarian data dan pengurutan data. sebagai contoh pada table pekerjaan disana tidak terdapat index, tentu hal ini sangat tidak disarankan, apalagi jika datanya besar. biasanya MySQL akan memberikan peringatan bahwa tidak ada index pada table ini. index disini, bisa berupa index biasa, unique ataupun primary. index yang baik adalah menggunakan tipe data numerik, kenapa ? (akan kita bahas nanti).
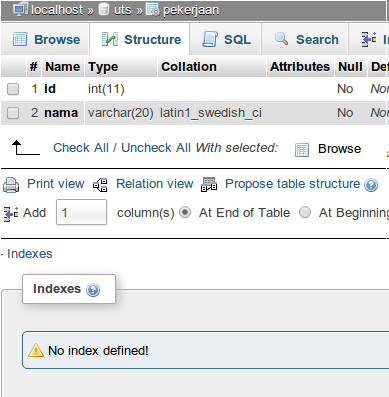
Pastikan Tiap Table memiliki Index
Sesuaikan Type Data. Utamakan Numerik
penggunaan tipe data juga sangat berpengaruh, jangan asal main Long Integer ataupun Varchar(10000), perlu adanya penyesuaian. mungkin bagi para pemegang rekening sudah tahu, bahwa data nama nasabah di bank biasanya kalau kepanjangan akan disinkat. atau laporan berita acara transfer uang, kalau kepanjangan pasti juga akan terpotong. hal ini untuk mengurangi resiko meningkatnya running time saat melakukan proses pada data. jika data yang memang kita butuhkan adalah varchar(200) kenapa harus disediakan varchar(10000), tentu sangat tidak efisien. selain itu seperti yang saya seinggung sebelumnya pengguna’an tipe data numeric adalah yang laing efisien terutama untuk index, kenapa ? tipe data String (Varchar, Text, Full Text) ataupun Binary (BLOB, GLOB) sangat tidak disarankan untuk dijadikan index (kecuali anda sangat terpaksa seperti nomor account pada accounting) karena index nantinya akan dijadikan sebagai acuan dalam pengurutan susunan data, tentu sangat tidak bijak jika kode tersebut terlalu panjang, atau terlalu banyak memakan byte. dalam hal ini tipe data numerik, terutama integer (lebih-lebih unsigned integer karena biasanya kita tidak membutuhkan data minus pada primary key atau bahkan bisanya memakai auto increment). dalam praktek yang saya lakukan pada jumlah data sebanyak 12.000 data, saya mendapati pencarian menggunakan integer jauh lebih cepat daripada yang lain.
satu lagi, soal tipe data numerik, juga perlu diperhitungkan panjang bytenya. untuk kode jenis kelamin misalnya, kenapa harus menggunakan table sendiri bernama table jenis_kelamin, yang mana disana hanya terdapat dua record, id 1 untuk laki-laki dan id 2 untuk perempuan. ini sangat tidak efisien, seharusnya cukup menggunakan tipe data bool saja. begitu juga untuk data lain, seperti kewarganegaraan, jika kita memiliki 4 field, untuk primary key, sebaiknya menggunakan cukup byte, jangan interger (apalagi Big Integer).
Hindari LinkedList gunakan Array
jika anda terpaksa menggunakan tipe data string, sebagai index terutama, sebaiknya gunakan yang tipe datanya fix, seperti varchar(100), sudah jelas dipastiakan bahwa panjangnya 100 karakter, ini akan sangat membantu dalam pemrosesan data, karena panjang datanya fix, pencarian dan prosesing-nya juga lebih cepat. berbedata dengan tipe data Text, tipe data ini contiguous alias berkesinambungan, terkadang datanya ter-fragment (apalagi kalau sering melakukan proses update, panjang data-nya berubah-ubah).
Tata Ulang Table
pada awal sebauh database itu di buat, isinya masih kosong. ketika sudah ditambah dengan berbagai macam data, operasi update, insert, delete, dan lain-lain. tentu table tersebut menjadi tidak tertata, ada banyak perubahan data yang sudah terjadi di dalamnya. solusinya adalah dengan melakukan Optimasi pada table dengan syntax Optimize, (misal : Optimize Table Penduduk). cara yang lebih bagus lagi adalah dengan meng-export table anda dahulu ke bentuk file sql, kemudian kosongkan isinya (dengan melakukan TRUNCATE bukan DELETE FROM TABLE ), baru import lagi file sql ke dalam table anda. ini membuat seolah table anda adalah table fresh baru.
Design Ulang ERD
jika memang dibutuhkan silakan design ulang database anda, terkadang penggunakan redudant data akan mempercepat proses walaupun nanti cost di storage (tapi saya rasa boros storage tidak masalah, karena ukuran harddisk saat ini sudah sangat-sangat besar).
Kurangi Penggunaan Table
cek apakah ada table yang bisa dikurangi isinya, atau bisa dihapus, seperti table jenis_kelamin, warga_negara (jika cuma WNA dan WNI lebih baik gunakan bool saja), lakukan pula normal chomsky dan lain-lain. ini akan sangat membantu dalam manajemen database.
Lakukan Partition
partition adalah memecah table menjadi beberapa table, hal ini disebabkan karena satu table terlalu menamung banyak data. misalnya saya memiliki table penduduk, yang mana disana terdapat alamat, jumlahnya ada 10 juta penduduk, terbagi dalam 10 kota. jika saya menjadikan data penduduk itu hanya ada pada satu table, lalu saya mencari satu orang penduduk yang bernama Nurul Huda di kota Lamongan, berarti saya mencari 1 orang dari 10 juta data, tentu ini akan sangat lama, bandingkan jika kita pecah, masin-masing kota akan memiliki 1 table penduduk (misalkan table penduduk_lamongan adalah table khusus penduduk di kota lamongan, penduduk_surabaya adalah table khusus penduduk di kota surabaya). anggap ada 10 kota, berarti ada 10 table, dan masing-masing table berisi 1 juta data. dengan satu kriteria saja (yakni kota : misalkan lamongan) saya sudah mempersempit pencarian dari pencarian 1 orang pada 10 juta data, menjadi 1 orang pada 1 juta data, karena saya hanya perlu melakukan pencarian pada table penduduk_lamongan, bukan pada table penduduk secara keseluruhan.
Pakailah Cache
untuk operasi – operasi agregate seperti SUM, COUNT dan lain-lain ada baiknya disimpan sendiri dalam sebuah table tertentu, kita bisa menggunakan flag atau sejenis keyword untuk membuat data ini. misalkan jumlah penduduk laki-laki di lamongan, dari pada saya melakukan SELECT count(*) FROM penduduk_lamongan WHERE jenis_kelamin=’1′ , lebih baik saya membuat sebuah table bernama cache yang mana menyimpan record bahwa penduduk_lamongan yang laki-laki saat ini sebanyak sekian. sehingga ketika saya butuh jumlah penduduk saya cukup SELECT jumlah WHERE name=’ total_lamongan_pria’ dari table cache.
Hindari Union
union membutuhkan waktu yang lebih banyak dibandingkan operasi lain, sebisa mungkin hindari union lebih baik menggunakan nested query daripada union, dan daripada nested query lebih baik membuat view dahulu, daripada membuat view dahulu untuk di query lagi, mendhing usahakan hanya membuat satu query langsung sekali jalan.
Utamakan JOIN daripada WHERE
JOIN walaupun sama dengan where, pada banyak kasus (hampir seluruhnya) JOIN jauh lebih cepat dibandingkan dengan WHERE, terutama untuk hubungan antar table. kecuali jika anda menggunakanya untuk pencarian berdasarkan “string” atau data tertentu.
Sebaiknya ORDER BY id yang interger.
untuk orderby atau pengurutan data bedasarkan kriteria tertentu akan sangat baik jika anda menggunakan id yang berupa integer daripada berupa text atau varchar. mengapa, cukup logis pengurutan berdasarkan integer tentu lebih cepat karena secara programming mengurutkan “Integer” jauh lebih cepat daripada mengurutkan “String”.
Utamakan Match Against daripada LIKE pada pencarian Text
walaupun kita sudah mencoba untuk menghindari pencarian menggunakan String terkadang kita memang perlu melakukan pencarian memakai String. anggaplah kita punya 5 Field, “Nama, Istri, Motto, Biodata, Keterangan” jika kita ingin mencari sebuah data tertentu bisanya kita memakai WHERE seperti ini “WHERE nama LIKE ‘apa’ OR istri LIKE ‘apa’ O Motto LIKE ‘apa’ OR biodata LIKE ‘apa’ OR keterangan LIKE ‘apa’ “. cara seperti ini tentu tidak efisien, akan lebih cepat jika kita menggunakan Match Again. sehingga syntax akan menjadi “WHERE Macth(nama,istri,motto,biodata,keterangan) Againts (‘apa’)” .
Gunakan Hindari *
sebisa mungkin anda menghindari ” SELECT * FROM ” karena tanda * akan memanggil semua field, padahal anda hanya membutuhkan beberapa field saja. secara programming memang tidak ada salahnya, tapi jika komputer server PHP misalnya dan komputer MySQL adalah komputer yang berbeda yang mana keduanya terpisah pada jaringan yang berbeda pula, tentu akan lebih cepat jika kita memanggil data yang dibutuhkan saja, karena penggunaan * akan memanggil semua field yang berarti semakin banyak fieldyang harus dikirimkan padahal yang dibutuhkan hanya 2 atau 3 field saja.
Gunakan Limit
dalam Programming ada istilahnya Pagination , ini dibuat bukan tanpa alasan. untuk data dengan jumlah raksasa tentu akan lebih mudah jika mengambil beberapa daa tertentu saja yang dibutuhkan (mirip dengan kasus * ). pengambilan data sejumlah 10.000.000 data dalam satu waktu bukan hal bijak, lagi pula user juga tidak mau kalau harus memandang langsung 10 juta data dalam satu waktu, lebih baik perlihatkan 20 data, kemudian di paginate ( next – prev).
